


For most finance teams, invoice processing feels deceptively deterministic.
An invoice enters the system. Data gets extracted. Validation happens. The transaction either passes or fails. At least in theory, the same invoice should always produce the same result.
But anyone who has spent enough time inside enterprise Accounts Payable operations knows that reality behaves differently.
Two invoices that appear visually identical can move through the same AP system and produce completely different outcomes. One clears straight-through processing without friction. The other enters an exception queue, fails validation, or never reaches ERP posting at all.
What makes this especially frustrating is that the discrepancy often cannot be explained by looking at the document itself. To the AP analyst, both invoices look the same. To the system, they may not be the same object anymore.
This is one of the least discussed invoice processing errors in enterprise finance systems today, and it exposes a much deeper issue inside modern AP operations.
What Are Invoice Processing Errors?
Invoice processing errors occur when an AP system incorrectly extracts, interprets, validates, routes, or posts invoice data during the Accounts Payable workflow, including extraction, validation, PO matching, tax interpretation, approval routing, or ERP posting.
Critically, invoice processing errors are not the same as invoice errors. An invoice error is a mistake on the document itself (wrong amount, missing PO number). An invoice processing error happens when a correct invoice fails somewhere inside the processing system.
Common types of invoice processing errors include:
- Failed or incorrect PO matching
- Duplicate invoice detection failures
- Tax validation mismatches
- Incorrect vendor associations
- Currency interpretation issues
- Approval workflow exceptions
- ERP posting failures
In modern AP environments, many invoice processing errors originate not from missing data, but from how systems interpret contextual variance across documents.
Why Can Two Identical Invoices Produce Different Outcomes?

Enterprise AP systems rarely operate on certainty.
Underneath the interface, most invoice processing workflows depend on probabilities, spatial relationships, contextual mapping, and learned document structures. What appears deterministic at the workflow level is often probabilistic at the model level.
This creates a strange paradox.
A finance team may receive two invoices from the same vendor:
- same logo
- same invoice structure
- same line-item placement
- same totals
- same PO format
Yet one invoice processes cleanly while the other enters manual review.
Why?
Because the system is not actually “seeing” the invoice the way a human does.
It is interpreting:
- Coordinate positioning — where fields appear in the document space
- Document hierarchy — how elements relate structurally
- Field confidence scores — the probability that extracted values are correct
- Contextual proximity — how fields relate to surrounding content
- Validation dependencies — whether extracted values satisfy downstream business rules. A one-centimeter layout shift may not matter to a person reviewing the document. But inside the model pipeline, that shift can alter how the invoice is internally represented.
That is where many invoice processing errors begin.
What Is Invoice Processing Variance?
Invoice processing variance refers to inconsistent outcomes when the same or similar invoices are processed through an AP system, where structural, contextual, or metadata differences cause the same document type to succeed in some instances and fail in others.
At scale, invoice processing variance compounds into:
- Growing exception queues that require manual intervention
- Unpredictable straight-through processing rates
- Recurring duplicate invoice risks across entity boundaries
- Inconsistent compliance outcomes across geographies
The Math Behind the Invoice Processing Error: Probabilistic AI vs. Rule-Based Logic
Traditional AP systems were designed around deterministic logic. If a field appeared at a fixed coordinate, the system extracted it the same way every time. But modern AI-based invoice systems operate probabilistically. They assign confidence scores to extracted values based on document structure, contextual relationships, and historical behavior.
This is where many Invoice processing errors begin. A slight distortion in scan quality, spacing, or rendering can reduce a confidence score from 0.98 to 0.96. To a human reviewer, the invoice still appears identical. To the model, however, the probability threshold may no longer satisfy downstream validation logic. may no longer satisfy downstream validation logic.
This is a core driver of Invoice processing variance.
What is "Layout Drift" and Why is it The Hidden Trigger for Processing Failures
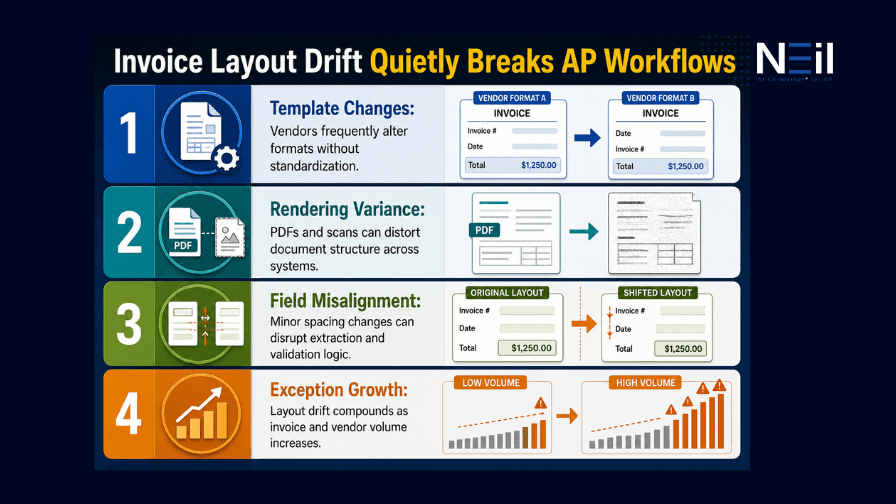
Invoice layout drift occurs when vendors make small formatting or structural changes to their invoice templates over time. Even minor adjustments, a logo that shifts position, spacing that changes, line items that move lower on the page, a PDF export setting that changes rendering — can disrupt how AP systems interpret the document.
Most AP systems quietly depend on structural consistency. They learn the positional relationships between:
- Invoice totals and tax fields
- Vendor identifiers and PO references
- Line items and approval-relevant fields
When a vendor's billing software is updated, or their ERP changes PDF export behavior, the invoice may shift by only 2–3 millimeters. To a human reviewer, nothing has changed. To a legacy OCR engine with fixed coordinate anchors, the field is now in the wrong zone — and the extraction fails.
Layout drift is one of the biggest hidden drivers of invoice processing errors in large-volume AP environments, and most AP teams never explicitly track it. They classify the resulting exceptions as random operational noise when they are in fact a predictable, systemic pattern.
Why High Extraction Accuracy Doesn't Prevent Invoice Processing Errors?
Most AP vendors continue to position extraction benchmarks as the primary indicator of system performance. But high OCR scores rarely reflect production reliability.
A system may achieve excellent extraction performance while still producing recurring Invoice processing errors downstream. This happens because extraction only confirms whether text was captured correctly. It does not confirm whether the invoice can successfully survive validation, workflow orchestration, tax interpretation, ERP posting, or approval routing. This is why invoice processing accuracycannot be measured at the extraction layer alone.
It frequently occur after successful extraction, at the stages of:
- Currency normalization — an extracted amount fails because the currency context was misinterpreted
- Tax interpretation — a correctly extracted percentage triggers a compliance exception under a different jurisdiction's rules
- Vendor mapping — formatting variation causes the vendor association to shift
- PO matching — confidence drops below the matching threshold due to semantic inconsistency
- Approval routing — logic routes incorrectly based on entity or category misclassification
PO Association: Why “Freight” vs “Shipping” Triggers Validation Errors
PO matching failures are often treated as extraction issues, but many originate from semantic inconsistency instead.
A vendor invoice may reference “Freight” while the PO uses “Shipping.” The extracted values are technically correct, yet the system fails to associate them confidently because the semantic relationship between the terms was never understood.
This is where traditional automation pipelines plateau. Rule-based systems struggle when operational language deviates from expected terminology. As invoice volume increases, these semantic mismatches compound into larger Invoice processing errors and recurring exception queues.
Modern AP systems increasingly rely on contextual interpretation layers and Intelligent Character Recognition ICR models to understand meaning, not just text placement.
Why Scan Resolution and Metadata Affect “Identical” Documents?
Enterprise AP systems do not process invoices as static visual files alone. They also interpret metadata, rendering patterns, image quality, and document encoding behavior.
A scanned invoice with slightly lower DPI, altered compression, or different PDF rendering metadata can behave differently inside extraction pipelines. Even when the invoice appears visually identical, the internal document representation may shift significantly enough to trigger different confidence outcomes.
This is why many organizations struggle to improve invoice processing accuracy despite maintaining standardized vendor templates. The issue often lies not in the visible document, but in the invisible document behavior underneath it.
Over time, this creates recurring Invoice processing variance that AP teams mistakenly classify as random operational noise.
GCCs and Shared Services Magnify Invoice Processing Variance
Invoice processing errors become even more difficult inside GCC and shared services environments.
Global Capability Centers operate under conditions most AP systems were never originally designed for:
- multilingual invoices
- cross-border tax structures
- varying vendor behavior
- entity-specific approval logic
- currency normalization
- region-specific compliance requirements
In GCC environments, the same invoice field may require completely different validation logic depending on geography, entity structure, tax treatment, ERP configuration, vendor category or compliance jurisdiction. A vendor invoice processed automatically under one entity may trigger escalation under another, despite containing nearly identical data.
This is why high-volume GCC environments experience elevated levels of Invoice processing variance even when invoice formats appear standardized. The complexity exists inside the validation logic, not necessarily inside the document.
OCR vs ICR for Invoices: A Technical Comparison for Finance Leaders
The debate around OCR vs ICR for invoices is no longer about extraction speed alone. It is fundamentally about workflow reasoning capability.
| Capability | Traditional OCR | Intelligent Character Recognition (ICR) |
|---|---|---|
| Extraction Method | Fixed coordinate / zone-based | Contextual, relationship-aware |
| Layout Sensitivity | High (breaks on minor drift) | Low (adapts to structural change) |
| Semantic Matching | No | Yes |
| Confidence Scoring | Binary pass/fail | Probabilistic with threshold tuning |
| Learning Loop | Static retraining | Reinforcement learning from corrections |
| Multi-Entity Validation | Limited | Native |
| Multilingual Support | Template-dependent | Context-aware |
Traditional OCR systems read visible characters from predefined document zones. ICR models evaluate contextual relationships between fields, vendor behavior, historical patterns, and workflow dependencies simultaneously.
This distinction becomes operationally critical when layouts drift continuously, invoices span multiple languages, approval structures vary by entity, or validation rules evolve with regulatory changes.
What Modern AP Systems Need Instead
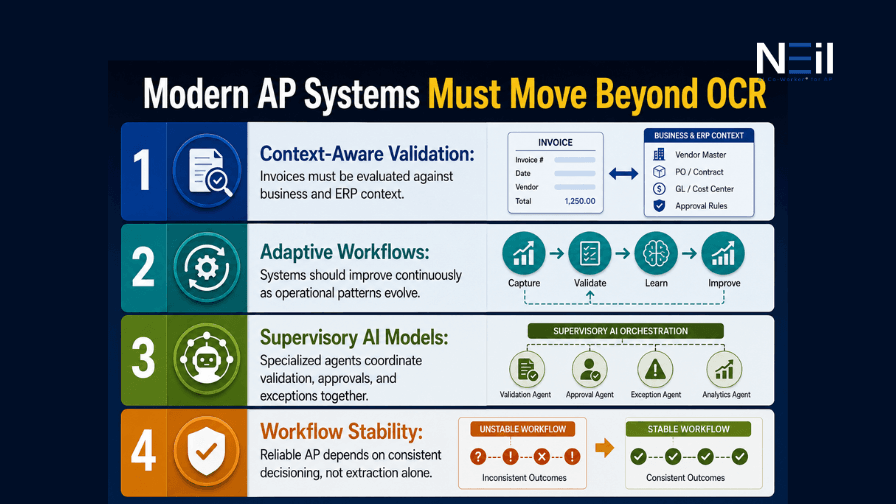
Modern Accounts Payable transformation requires systems that operate beyond extraction alone.
The future of AP is increasingly centered around:
- Intelligent Character Recognition (ICR)
- Context-aware validation
- Reinforcement learning loops
- Probabilistic decisioning
- Workflow orchestration
- Operational reasoning
The objective is no longer:
“Can the system read the invoice?”
The objective is:
“Can the system move the invoice through the workflow reliably without creating downstream operational instability?”
Modern systems must continuously evaluate:
- contextual relationships
- historical transaction patterns
- vendor behavior
- workflow dependencies
- approval consistency
- validation confidence
This is also why AP transformation is increasingly moving toward supervisory AI models where specialized agents coordinate across ingestion, validation, ERP posting, and exception handling workflows instead of functioning as isolated OCR engines.
Invoice Processing Errors Are Ultimately Variance Problems
Most enterprises still describe invoice processing errors as isolated operational issues.
But at scale, they are usually variance management problems.
The system is not failing because invoices are unreadable. It is failing because enterprise finance environments contain enormous contextual ambiguity:
- Vendors change their invoice formats without notice
- Layouts drift subtly across billing software updates
- Tax logic evolves with regulatory changes
- Approval paths fragment across entities and geographies
- ERP configurations shift with system upgrades
- Exception queues grow as variance compounds
Two identical invoices producing different outcomes is therefore not a glitch.
It is a reflection of how much uncertainty exists underneath enterprise AP operations.
FAQs
An invoice processing error occurs when an accounts payable system fails to correctly extract, validate, route, match, or post invoice data during the AP workflow. Invoice processing errors are distinct from invoice errors (mistakes on the document itself), they happen when a correct invoice fails somewhere inside the processing system, typically due to layout drift, confidence scoring failures, semantic mismatches, or business logic exceptions.
What is invoice processing errors?
An invoice processing error occurs when an accounts payable system fails to correctly extract, validate, route, match, or post invoice data during the AP workflow. Invoice processing errors are distinct from invoice errors (mistakes on the document itself), they happen when a correct invoice fails somewhere inside the processing system, typically due to layout drift, confidence scoring failures, semantic mismatches, or business logic exceptions.
What is invoice layout drift?
Invoice layout drift occurs when vendors make small formatting or structural changes to invoices over time. Even minor adjustments in spacing, positioning, rendering, or document structure can impacthow AP systems interpret invoice data internally.
What causes invoice processing errors in automated systems?
The most common causes are legacy OCR coordinate failures, layout drift (where fields shift by millimeters), scan noise (low DPI), and probabilistic AI thresholds failing to meet confidence scores.
How does "Invoice Layout Drift" trigger processing failures?
Layout drift occurs when a vendor updates their invoice template, shifting data fields. Legacy systems that rely on rigid "anchor points" fail to find the data, resulting in a processing error.
Why is extraction accuracy not enough in invoice processing?
High extraction accuracy only measures whether fields were captured correctly. Invoice processing also depends on downstream validation, tax interpretation, ERP mapping, workflow routing, and exception handling, where many operational failures actually occur.
How do modern AP systems reduce invoice processing errors?
Modern AP systems use Intelligent Character Recognition (ICR), context-aware validation, reinforcement learning loops, anomaly detection, and decision-centric workflow orchestration to improve processing reliability across variable invoice environments.
Can AI eliminate duplicate invoice inaccuracy?
Yes, by using reasoning-centric Agentic AI that recognizes an invoice regardless of layout shifts or metadata changes.